Chromium RV32
Status: feature complete (QEMU)
A reproducible, source-light recipe for building Chromium's content_shell (and a
standalone V8 d8) for riscv32-linux-gnu, booting it under qemu-system-riscv32, and driving a modern Svelte 5 application through SSR
hydration, reactive DOM updates, fetch round-trips, SSE streaming, and a real
interactive GUI session over VNC.
As of milestone M10 the QEMU-validated scope is feature complete. The V8 correctness work that
was deferred at the original public-alpha tag — the InterpreterEntryTrampoline OSR-urgency-scratch SEGV (M9) and the kAtomicsLoad register-allocator-verifier bug (M10) — has been root-caused
and fixed in tree. Sparkplug and Maglev remain off on RV32 by design (see “What's
intentionally out” below); everything else lands.
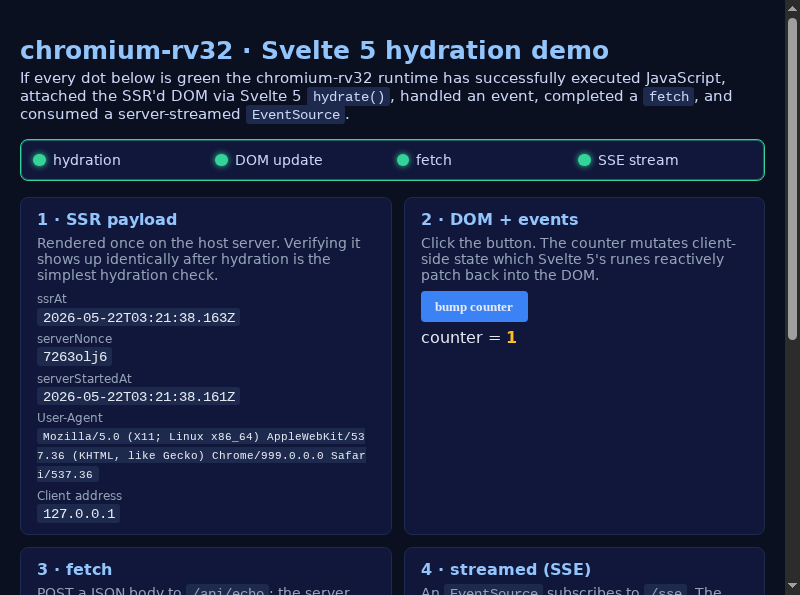
content_shell inside the rv32 guest. The PNG was
captured via Page.captureScreenshot after the page emitted m6:all-green — i.e. SSR hydration, DOM update, fetch POST, and
the SSE stream had all converged.Why bother?
Upstream V8 deprecated its RV32 backend, and Chromium has never officially supported 32-bit RISC-V. This project pins the last viable V8 commit, applies a minimal set of build- and runtime-side patches across V8, Chromium, and a handful of third-party modules, and ships the whole thing as a Buildroot-based bootable image you can run on stock QEMU. The point is not a shippable browser — it is a working artifact that proves a modern JS engine, a real web platform, and a Svelte 5 SPA can still be made to converge on RV32GC Linux today.
What it actually does
- SSR + hydration with
onMount()firing inside the guest. - Rune-driven reactive DOM updates from a Svelte 5 counter.
fetchPOST round-trips to a host-side echo server over user-mode networking.- Server-Sent Events streaming in once per second.
- A host-side CDP→RFB bridge that exposes
content_shell's framebuffer to any VNC client and forwards pointer / key events back as CDPInput.dispatch*calls. - Convergence proof: a single Svelte
$effectlogsm6:all-greenonce all four lights are on, andPage.captureScreenshotreturns the pixels above.
Correctness fixes landed
- M9 — trampoline OSR-urgency scratch (V8). On RV32,
kJavaScriptCallDispatchHandleRegisterresolves tono_reg, which let the allocator handa4tofeedback_cellwhile upstream V8 was simultaneously passing a hard-codeda4as a scratch register toResetFeedbackVectorOsrUrgency. The collision corruptedfeedback_celland SEGV'd later in the budget-interrupt sequence. Replacing the hard-coded scratch with one acquired viaUseScratchRegisterScope::Acquire()restores the normal interrupt-budget tier-up path on RV32. The M6 workaround that disabled that path is gone. - M10 —
kAtomicsLoadregister-allocator pin (V8). The rv32InstructionSelectorforRiscvWord32AtomicPairLoaddeclared its(base, index)inputs with the genericg.UseRegister(...)policy while pinning its(low, high)outputs to FIXEDa0/a1. The allocator could then picka2for both the address input and a spill destination, and the constraint resolver would emit[a2 := a0]right before the load — overwriting the address. Pinning(base, index)to FIXEDa3/a4closes the hole.v8_enable_concurrent_mksnapshotis back on, the full upstream--turbo_verify_allocationruns, andAtomics.loadagainstBigInt64Arrayreturns the correct value.
V8 tier state
| Tier | State | Notes |
|---|---|---|
| Ignition | On | Baseline interpreter. |
| Turbofan | On | Interrupt-budget tier-up restored by M9. |
| Turboshaft | On | Full upstream --turbo_verify_allocation as of M10. |
| LiftOff (Wasm) | On | Codegen static-asserts patched; not exercised by the demo. |
| Sparkplug | Off (declined) | Out of scope for RV32 here — see below. |
| Maglev | Off (declined) | Out of scope for RV32 here — see below. |
What's intentionally out
- Sparkplug. M10 confirmed that
v8/src/baseline/riscv/already shares its rv32 codegen with rv64 throughkSystemPointerSize-parameterised helpers, so the rv32 path is plausibly correct. In practice, enabling it makes the torque-csa graph large enough to trigger clang frontend signals under default ninja parallelism on the build hosts I care about. Not a tier-down bug, just build-side memory pressure for a tier that does not move the needle on a TCG-bound workload. Declined for RV32. - Maglev.
v8/src/maglev/riscv/maglev-ir-riscv.cccarries theV8_TARGET_ARCH_RISCV32ifdefs, but the wider Maglev integration — deopt-frame layout, on-stack-replacement, the tier-up trampoline — has not been audited under the M9 trampoline fix. Auditing that surface to land Maglev on RV32 is real work that, again, would not move the needle on a TCG-bound demo. Declined for RV32. - Real RV32 hardware. The pipeline is portable in principle, but everything
here is validated on
qemu-system-riscv32only. Bringing it up on an Efinix Ti375 or a SiFive U-series part is a separate exercise. - SwiftShader, Dawn, Vulkan, ANGLE, FFmpeg. Upstream simply does not ship RV32 backends for the SwiftShader Subzero JIT or the Chromium FFmpeg config; rendering goes through Skia's CPU rasteriser and there is no audio / video decode path. Fine for HTML / CSS / 2D canvas; not fine for WebGL or media.
- Sandbox / multi-process.
content_shellruns with--single-process --no-sandbox; the seccomp filters and zygote on RV32 are untested.
Performance, honestly
On a Ryzen 9 5950X / 32 GB WSL2 host, cold QEMU boot to the Buildroot prompt is 1–3 s, d8 hello.js first call is 1.5–3 s (and 0.2–0.5 s when JIT-cached), content_shell --dump-dom on a data: URL is 30–60 s, and the
Svelte 5 demo reaches m6:all-green in roughly 75 s from QEMU start. M7 VNC
click-to-frame latency is 0.3–1.2 s. These numbers are dominated by QEMU TCG translation, not by V8 tier-down — on real RV32 silicon the
shape would be very different.